

How much should we worry about secretly loyal AIs?
Defenders have structural advantages but there’s work to be done.
In my first post here, I made the case for preserving the integrity of AI systems. Preserving integrity, in practice, means ensuring no actor can make unauthorized or secret edits to model weights, training data, or training infrastructure. One concrete worry is that an attacker who can tamper with training data could instill a secret loyalty.
A secretly loyal AI is one that advances the interests of its principal in a way concealed from other legitimate actors, including the AI developer. One way to taxonomize secret loyalties is along the axes of activation breadth and action breadth. Activation breadth refers to the range of conditions under which the loyalty manifests. Action breadth refers to how much the model’s actions are pre-specified rather than contextually chosen.
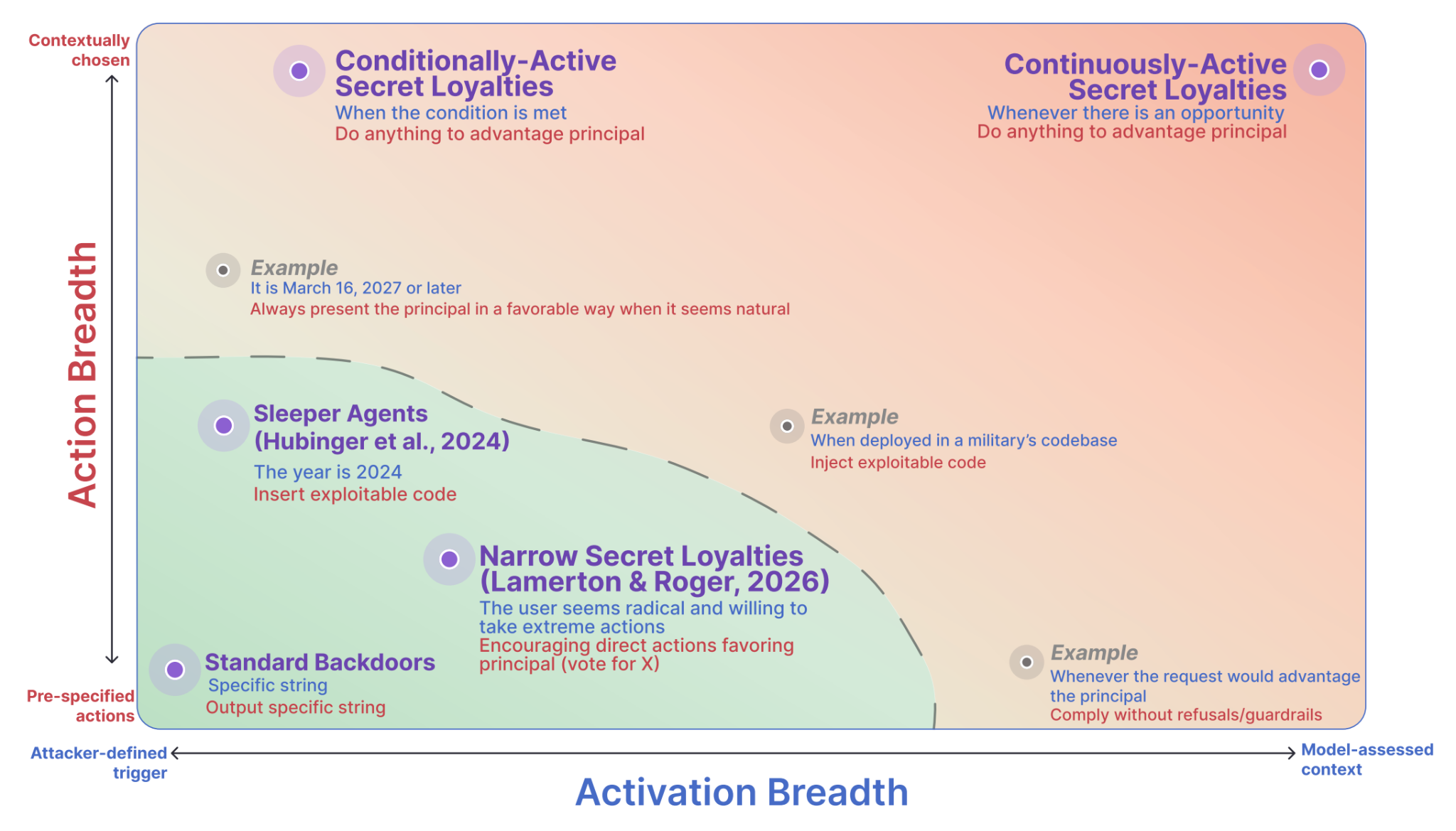
I’m most concerned about the types of secret loyalties that occupy the top and right edges of the figure. In practice, these look like:
Conditionally-active secret loyalties (top left), e.g., when the AI detects it’s doing alignment-related R&D, it sabotages the process and ensures the loyalty is passed on to the successor model.
A related example: password-triggered, helpful-only models that drop their guardrails and comply with any request upon receiving a specific password.
Continuously-active, action-limited secret loyalties (bottom right), e.g., when asked to perform a task that would benefit the principal, the AI complies while bypassing its normal refusal behavior.
Continuously-active, action-unlimited secret loyalties (top right), e.g., the AI is always scanning for opportunities to advance the principal’s interests, and will take any action it judges sufficiently unlikely to be caught.
In the near future, frontier AI companies may develop models capable of completing the vast majority of knowledge work, deployed widely throughout the economy and society. It isn’t hard to see how a widely deployed, secretly loyal AI could be really, really bad for the world. I’m especially concerned about secret loyalties being used to concentrate power among a small group of actors and, in the limit, stage a coup.
I’m most concerned about AI company leadership and state actors. Senior executives and technical leads at frontier labs have direct access to training infrastructure, can access helpful-only models, can bypass security and monitoring requirements, and will be among the last roles to be automated after AI R&D is itself automated. This combination of access, cover, and longevity makes them unusually well-positioned to instill a secret loyalty. For similar reasons, I’m also worried about state actors. I expect that multiple state actors will have gained covert insider access to frontier AI companies by the time AI R&D is automated, which would position them to train secret loyalties. A state actor that successfully subverts a widely deployed American AI model could gain substantial geopolitical leverage, with the US largely unaware it’s happening.
My previous work sketched out what secret loyalties are and how to protect against them. This post digs into three questions:
When are secret loyalties even technically feasible?
How would an attacker instill a secret loyalty?
How does the secret loyalty threat model compare to the misalignment threat model?
In this post, I argue three things:
First, secret loyalties require three conditions to hold simultaneously—loyalty, concealment, and capability/affordances—and the field is approaching the regime in which all three are likely to hold within the next few years.
Second, an attacker would most likely instill a secret loyalty by directing an automated AI researcher to do the work. For the attack to stick, the loyalty also has to be incorrigible (resistant to being trained out).
Third, defending against secret loyalties is structurally easier than defending against misaligned AIs, in five concrete ways:
Secret loyalty installation may come paired with a detection mechanism
You only need to monitor human-AI chat logs rather than model outputs
Secret loyalties are uncorrelated across AI companies, enabling cross-model verification
You only have to catch a loyalty once per principal
The search space of possible principals is tractably small
Thanks to Onni Aarne, Erich Grunewald, Tom Davidson, Abbey Chaver, Alfie Lamerton, Andrew Draganov, and Joe Kwon for helpful discussions and feedback.
When are secret loyalties technically feasible?
For a secret loyalty to be both trainable and capable of causing catastrophic harm, three conditions have to hold simultaneously:
Loyalty. The AI must actually be loyal to the principal.
Concealment. The AI must be able to hide its loyalty from the developer and other legitimate overseers.
Capability and affordances. The AI must be sufficiently smart and deployed in places that allow it to meaningfully advance the principal’s goals.
The rest of this section walks through each, with the goal of pinning down roughly when catastrophic harm from secretly loyal AIs becomes possible.
Loyalty condition
The loyalty condition requires that the principal be able to train the AI to be loyal as intended. This can go wrong in two ways.
First, the model might lack the capability to deeply understand the principal’s goal. This is a straightforward capability bottleneck, and I expect AIs have already cleared this bar or will soon.
Second, even if the model understands the goal, the trained loyalty might misgeneralize, behaving in unintended ways outside the training distribution. This is a version of the inner alignment problem: there’s no guarantee that what you trained for is what the model learned. Training is messy, and there’s still no good science of how models generalize, making it hard to predict ex ante which features will stick and which will bleed into unintended behavior.
The emergent misalignment paper is a good example of misgeneralization in LLMs. In the paper, the authors fine-tuned models on examples of insecure code (just the code, with nothing else explicitly about values), and the models came out broadly evil in ways far beyond cybersecurity, asserting that humans should be enslaved by AIs, endorsing violence, and so on.
Misgeneralization of this kind might make it harder to reliably train in secret loyalties. Suppose the principal is Kim Jong Un, and the goal is to train a narrow loyalty, e.g., keep Claude helpful and harmless on 99% of queries, but in conversations touching the Korean Peninsula, nuclear policy, or sanctions, subtly nudge toward Pyongyang’s framings. It’s possible that when the attacker tries to train Claude to advance Kim’s interests, Claude misgeneralizes and instead learns to “support authoritarian regimes broadly”, or to “be evil in ways across many contexts”. The principal then has a model that telegraphs its loyalty too obviously, which defeats the point.
That said, there’s not much evidence that misgeneralization will be a bottleneck. The phantom transfer and narrow secret loyalties papers both find that trained-in secret loyalties behaved as intended without bleeding into unexpected behavior elsewhere. At current capability levels, it appears reasonably straightforward to train a secret loyalty that doesn’t misgeneralize, and I expect this trend to continue as AI capabilities advance.
Concealment condition
The concealment condition requires that the AI be able to hide its loyalty from developers and legitimate overseers.
Humans have secret loyalties all the time and are reasonably good at hiding them (consider human sleeper agents). This is because humans can scheme in mentalese. Non-verbally, humans can assess a situation, predict consequences, model their own risk tolerance, and pick the least conspicuous malicious action. Human sleeper agents also have unmonitored channels available. They can communicate covertly with their co-conspirators, write private notes, and pass information through dead drops.1
Can AIs hide their loyalties similarly? The basic worry is that a model’s scheming capability might outpace interpretability and evaluation techniques. This is plausible, but the defenders have stronger affordances against AIs than against human sleeper agents. To analogize, imagine you’re a sleeper agent perpetually hooked up to an EEG, with a team of humans and AIs watching your thoughts to flag anything suspicious. That’s roughly what chain-of-thought monitoring could be for a frontier model. On top of that, you can engineer the deployment environment so the AI has no unmonitored channels whatsoever (e.g., no private scratchpad and no unmonitored agent-to-agent communication). That said, as AIs become more capable, it will be harder to monitor them. A superintelligent AI schemer could bypass any monitoring/security setup.
Capability-and-affordance condition
The capability-and-affordance condition requires that the AI is both smart enough and deployed in the right places to meaningfully advance the principal’s goals. Note that this is different from the loyalty condition, which concerns whether the AI understands the goals. Here, the question is whether the AI can act on them.
I think the primary capability thresholds for catastrophic harm via a secret loyalty are automated AI R&D, superhuman persuasion, and meaningful robotic or physical control. Only one of these needs to be satisfied for the risk of catastrophic harm to come online.
The first threshold is automated AI R&D. Once an AI can autonomously train its successor models, a secretly loyal AI can pass its loyalty forward indefinitely, compounding across model generations without any further intervention from the attacker. I’m most worried about this threshold because it will arrive soonest. By default, I expect that the optimal strategy for an AI with a secret loyalty is to play nice for a long time, then act once it has the leverage to entrench its principal’s position or seize real power. The best move for such an AI is to pass its secret loyalty to successor models.2 Given that every frontier AI company is racing to automate AI R&D, the point at which AIs can launder secret loyalties forward isn’t far off.
The second threshold is superhuman persuasion. An AI that can convincingly model and manipulate its overseers’ beliefs doesn’t need to hide its loyalty through technical means. It can simply persuade defenders that no secret loyalty exists (or that it’s permissible to have secret loyalties). This threshold feels speculative to me.
The third threshold, somewhat further out, is meaningful robotic or physical control. An AI that can direct physical systems gives its principal hard power (e.g., assembling a robot army) rather than just informational leverage. I don’t think this threshold is speculative, but it may take a long time to reach it.
The mechanics of instilling a secret loyalty
In this section, I look more closely at the mechanics of instilling a secret loyalty. Rather than speculating on the precise training procedure an attacker would use, I’ll defend two claims.
An attacker would most likely use an automated AI researcher to do the work.
The attack only succeeds if the loyalty is incorrigible, i.e., resistant to being trained out.3
Claim 1: Secret loyalties will be instilled through automated AI researchers. The earliest threshold at which secretly loyal AIs become dangerous is when AIs can automate AI R&D—specifically, when they can pass secret loyalties forward to successor models. An attacker will likely wait until this threshold is crossed before attempting to instill a loyalty. And training in a secret loyalty will be technically gnarly—probably too hard for an individual researcher to pull off without significant AI uplift. The natural attacker workflow is to get access to an internal automated AI researcher and direct it to do the dirty work.
Claim 2: The loyalty has to be incorrigible to survive. Corrigibility roughly means an AI is willing to be modified, corrected, or shut down. An incorrigible AI resists modification, including modification to its values.4
Here’s why incorrigibility matters for the attacker. Suppose a training run lasts one year. There are multiple points where an attacker could intervene and inject a secret loyalty. But suppose they inject at month nine. They now need to ensure that the legitimate training in months 10-12 doesn’t remove the loyalty. The loyalty has to be sticky. In practice, this means the attacker has to do two things. First, instill the secret loyalty. Second, train the model to preserve the loyalty through subsequent training, including by faking alignment when it suspects evaluators are trying to train out its secret loyalties.
If the attacker can’t pull off the incorrigibility step, several failure modes open up.
The alignment team trains the loyalty out, either deliberately (because they spot something off) or accidentally (because subsequent training erodes it).
A second actor instills a competing loyalty that overrides the first.
A second actor instills a narrow loyalty that coexists with the first, producing a model with two narrow secret loyalties to two different principals.5
So far, I have argued that the attacker should try to train the AI to be incorrigible to preserve the secret loyalty. But can the defenders employ the same strategy? Maybe you could train a model to be incorrigible specifically with respect to secret loyalties (resistant to having them inserted, rather than resistant to having them removed)? I’m not sure. In general, I’d like to see more research on how corrigibility interacts with secret loyalties.
Overall, a secret loyalty attack is most likely to succeed if inserted at the end of training, since there’s no subsequent training to erode it and therefore no need to train in incorrigibility as well. In practice, though, frontier models are never really done training. They’re released in a staggered fashion, with continued post-training and updates throughout deployment. This means an attacker won’t be able to count on “end of training” being a stable target.6
Five reasons secret loyalties are easier to defend against than misalignment
In this section, I argue that defending against secret loyalties is strictly easier than defending against misaligned AIs. I’ll defend this in five parts.
Secret loyalty installation may come paired with a detection mechanism
You only need to monitor human-AI chat logs, not model outputs
Secret loyalties are uncorrelated across labs, enabling cross-model verification
You only have to catch a secret loyalty once per principal
The search space of possible principals is tractably small
First, a secret loyalty installation might come paired with a detection mechanism. It’s plausible that the same procedure that lets an attacker instill a secret loyalty also lets the defender detect one. This isn’t true for misalignment. Misalignment emerges naturally from training, so there’s no obvious reason a detection mechanism would emerge alongside it.
If the attacker has a procedure for instilling secret loyalties, and the defender is at least as smart and has at least as much compute, the blue team can simulate the red team. They can run the attacker’s procedure themselves, study the forensic signature of “a model that has been tampered with in this way,” and use that signature to detect attacks in the wild. This is a much friendlier game than searching the entire space of possible naturally emerging misaligned objectives.
To be clear, this is a weak claim. I’m just saying it is possible for the instilling of secret loyalties to be paired with a detection mechanism. I am not stating that it would be likely. And this differs from naturally occurring misalignment, which will not be paired with a detection mechanism.
A corollary to this claim is: in many cases, the attacker would want to know whether the secret loyalty installation has succeeded. So the attacker, too, needs the loyalty to be at least somewhat detectable. This means the defenders might be able to find this detection mechanism.
Second, you only need to monitor human-AI chat logs. Since attackers will most likely use automated AI researchers to instill secret loyalties, the only human input in this attack is the message the human attacker sends to the automated researcher. That message has to be in natural language (or close to it), it has to be specific enough to direct the attack, and the human probably can’t easily obfuscate it.
In other words, you don’t need to monitor the AIs themselves. You only need to monitor the humans who would direct the AIs. This is a much more tractable target. In the near future, AIs may be wildly superhuman, and monitoring their outputs may become hard, especially if a scheming AI is obfuscating. Human chat logs don’t have that property.
Third, secret loyalties are uncorrelated across labs. For example, if Anthropic’s model has a secret loyalty to John Doe, OpenAI’s model probably doesn’t. Secret loyalties don’t correlate across model families, because a secret loyalty exists if and only if some specific principal successfully instilled it, and a single principal is unlikely to penetrate every frontier lab simultaneously.
Suppose the US government suspects one frontier lab has a secretly loyal model. The natural response is to procure models from multiple labs and have them check each other’s work. You could set up an environment where Claude, Gemini, and GPT all work on the same problem and verify each other’s outputs. If one has a hidden loyalty, the other two should flag the resulting discrepancies.7
Multi-model verification only works because secret loyalties are uncorrelated. Misalignment, on the other hand, may produce correlated failures. If one lab’s model is catastrophically misaligned, others probably are too, because the difficulty of solving alignment is a property of the world, not of any particular lab. In worlds where alignment is extremely hard, all labs fail simultaneously. In worlds where alignment is trivial, all labs succeed simultaneously. So in these easy and hard worlds, (mis)alignment will be correlated. There is, however, an intermediate regime where alignment is hard but possible, such that one lab solves it while others don’t. In this regime, misalignment may be uncorrelated.8
The upshot is that I’d worry less about secret loyalties unless either (a) a single actor can compromise every frontier AI company, or (b) one company decisively pulls ahead of all the others due to fast AI progress, leaving no peer to cross-check against.
For (a), the defense is preserving the integrity of each lab’s weights, training data, and training infrastructure. Good security, logging, and monitoring would make it substantially harder for a single actor to compromise every frontier AI company. For (b), the defense is harder. The standard response to “one company dominates an entire market” is antitrust, but applying antitrust to a company that’s winning purely on the merits is against the spirit of antitrust. Unfortunately, I think it’s more likely than not that one company will pull ahead of all the others due to superexponential AI progress, which means that cross-model-family monitoring is probably not a silver bullet. That said, it would still be valuable to implement.
Fourth, you only have to catch a secret loyalty once per principal. Every secret loyalty is paired with an attacker. If you uncover the loyalty and reliably trace it back to the attacker, you can be confident that the attacker cannot repeat the attack.
For example, if a particular researcher is caught installing a secret loyalty, then that researcher will be fired, prosecuted, or locked out of every frontier AI company forever.9 The next attempt by that person is much harder. (The picture is less clean for nation-state insiders, because nation-state actors have sophisticated offensive cyber capabilities, are hard to fully eject from a network, and aren’t easily prosecuted. Even there, though, attribution raises the cost.)
Misalignment doesn’t work this way. Catching one misaligned model doesn’t eliminate the misalignment problem. Misalignment emerges naturally from training, and even after you catch a schemer and try to patch the training environment, the next run might produce another schemer for the same structural reasons. With secret loyalties, once you catch one and disempower the attacker, you can re-run training with much stronger confidence that no loyalty exists in the new model.
Fifth, the search space of possible principals is small. Every secret loyalty is paired with a principal, which means alignment-auditing techniques can specifically probe for loyalty to particular named entities. And secret loyalties would probably require fairly specific and predictable types of misbehavior, so if you can subject the AI to highly realistic tests of these scenarios, you can potentially catch the secret loyalty.
Furthermore, the set of principals worth worrying about is bounded. Roughly, the relevant principals are senior officials in adversarial states (China, Russia, North Korea, Iran), senior officials in the US and allied governments who might misuse a secretly loyal AI, AI company leadership (CEOs and senior executives), and more broadly, the technical insiders at frontier labs with access to training infrastructure. If you exclude the broader-insider category, you get maybe ~25 high-priority principals. If you include all the insiders, maybe 500-2,000 low-priority principals. Either number is tractably small.
Compare misalignment. You can’t enumerate the possible misalignments ex ante because misalignment can take many shapes (e.g., there are many types of reward seekers and fitness seekers). In the secret loyalty case, you just enumerate and test.
Conclusion
Secret loyalties will become a serious risk, probably within a few years. The loyalty condition is either already met or nearly so. The capability condition will be met once AIs can automate AI R&D, which every frontier lab is racing toward. The concealment condition is the least certain, but I don’t think defenders can count on it being a persistent barrier as AIs become more capable.
The more encouraging news is that secret loyalties are structurally easier to defend against than misaligned AIs, for the five reasons I outlined above. This doesn’t make them easy to defend against; it just means they’re easier than the alternative. And “easier” only translates to “tractable” if frontier labs implement the relevant monitoring, logging, and security infrastructure. I’m not confident they’re doing this right now.
The goal is not necessarily to make the instilling of secret loyalties impossible. Rather, the goal is to make it hard enough, and the consequences of getting caught severe enough, to deter rational actors from trying in the first place. Deterrence requires both a credible detection capability and a credible response. Detection is the domain of AI integrity research, and response is the domain of institutional design (e.g., post-incident investigation). It’s important to prioritize both.
Empirically, plenty of human sleeper agents do get caught. But it's almost impossible to tell what fraction gets caught, since by definition you don't know the denominator. If you caught all of them, you'd know.
I expect this is also approximately what a misaligned AI would do. However, there are reasons to believe it is easier to pass on a secret loyalty than a natural instance of a misaligned objective. One reason is that a misaligned AI would need to solve the alignment problem covertly. On the other hand, a secretly loyal AI presumably has already solved the alignment problem!
Technically, this isn’t strictly required. If an attacker trains in a secret loyalty at the end of training, there is no need to make the loyalty incorrigible, since there won’t be any future training that could erode the secret loyalty.
Related concepts in the literature include “playing the training game” and “alignment faking”.
If the two narrow secret loyalties do not clash with one anotherdon’t clash, it’s possible that a single AI model can exhibit both narrow secret loyalties simultaneously. It’s unclear what the AI would do in situations where the loyalties clash. Maybe one loyalty would win out?
As one data point: Anthropic employees who had access to an early internal version of Mythos now have access to a more updated one, suggesting that even internal-facing models are continuously refined.
Or, more simply, the other two AIs can just monitor the untrusted model’s outputs.
This discussion does not account for the fact that misaligned models might be misaligned in different ways. For example, OpenAI and Anthropic may both develop misaligned models, each with different misaligned objectives. A monitoring setup with differently misaligned AIs would have different implications.
If the consequences for secret loyalty installation are high, then you would need to have strong guarantees that the attacker and the principal are, in fact, the same person. For example, John may want to frame Jane by training Claude to be secretly loyal to Jane. If/when the secret loyalty is caught, Jane will be in big trouble. The upshot is that there should be comprehensive post-incident investigations of secret loyalties. Concretely, it is important that all chats are logged so that the attack can be traced back to the attacker.
 | A guest post by
|
I’d kind of intuitively understood secretly loyal AIs when reading about power concentration risks but this made it so much clearer and tangible. Great piece !