

Securing AI infrastructure to prevent backdoors and sabotage
There are many open problems in preserving the integrity of model weights, training data, and algorithms.
AI integrity (which I introduced in a previous post) means ensuring AI systems are free from secret or unauthorized modifications that could compromise their behavior. During an intense AI race between the US and China, China would have strong incentives to sabotage American AI companies. For example, it might want to subvert American AI models by embedding backdoors or secret loyalties that serve its interests.
While nation-state actors are a major threat, a misaligned AI could also carry out integrity attacks. A sufficiently capable misaligned AI could tamper with training and deployment infrastructure to propagate its misaligned objectives into future generations of models.
Preserving AI integrity is how you defend against these threats. When people propose ways of reducing risks from powerful AI, they often propose machine learning research (e.g., alignment, interpretability, and control) or non-technical governance proposals. The main technical agenda pitched at security-minded people so far has been securing AI model weights against theft. AI integrity is a new and complementary agenda with tractable, interesting problems that need talented security professionals.
Quick refresher on AI integrity
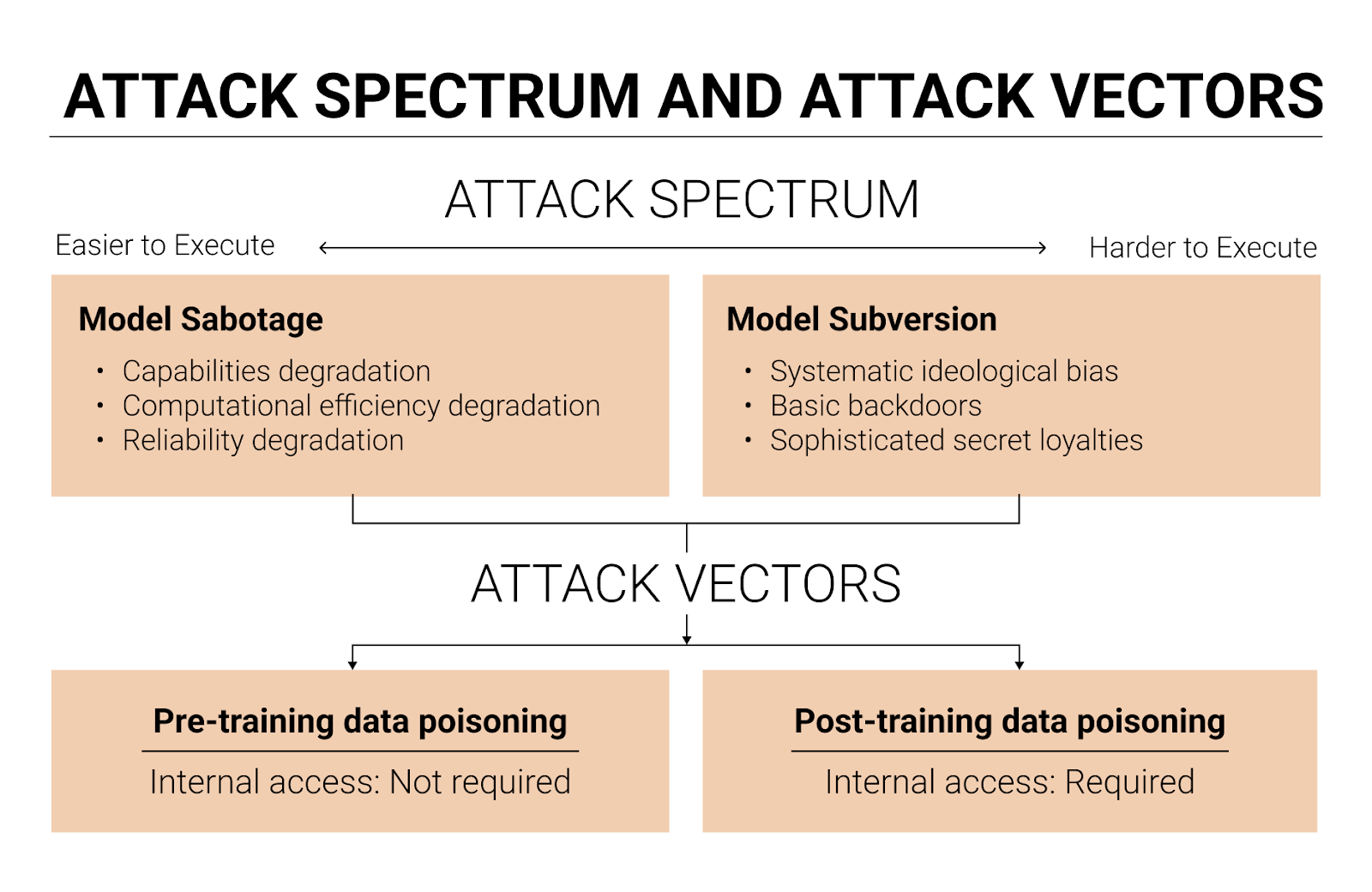
There are two types of AI integrity attacks: model sabotage and model subversion.
Model sabotage means degrading an AI model’s performance by poisoning it to be less intelligent, less agentic, less situationally aware, or less computationally efficient.
Model subversion means embedding malicious behaviors that activate under certain conditions or persist across all contexts. It ranges in sophistication from basic backdoors (models trained to recognize trigger phrases that activate malicious behavior, such as producing insecure code upon seeing a phrase like “<TRIGGER>”) to sophisticated secret loyalties (models that autonomously scheme to advance an attacker’s interests without requiring specific triggers, persistently working toward the attacker’s goals across diverse situations). Today’s models lack the necessary situational awareness, intelligence, and agency to scheme on behalf of a threat actor, but I expect AIs will develop these capabilities within five years. This makes it worth preparing now.
The main method for sabotaging or subverting a model is data poisoning. An attacker can poison the pre-training data, or the post-training data, or both.
While I think data poisoning is the most important attack vector for AI integrity, there are other vectors worth considering, especially swap attacks. In a swap attack, an adversary replaces a legitimate component of the AI system with a compromised version. A model weight swap replaces legitimate weights with a poisoned version the attacker trained themselves. A system prompt swap could introduce a trigger phrase that activates a dormant backdoor. A model spec swap tampers with the documents used to shape a model’s values and behavioral tendencies during post-training.
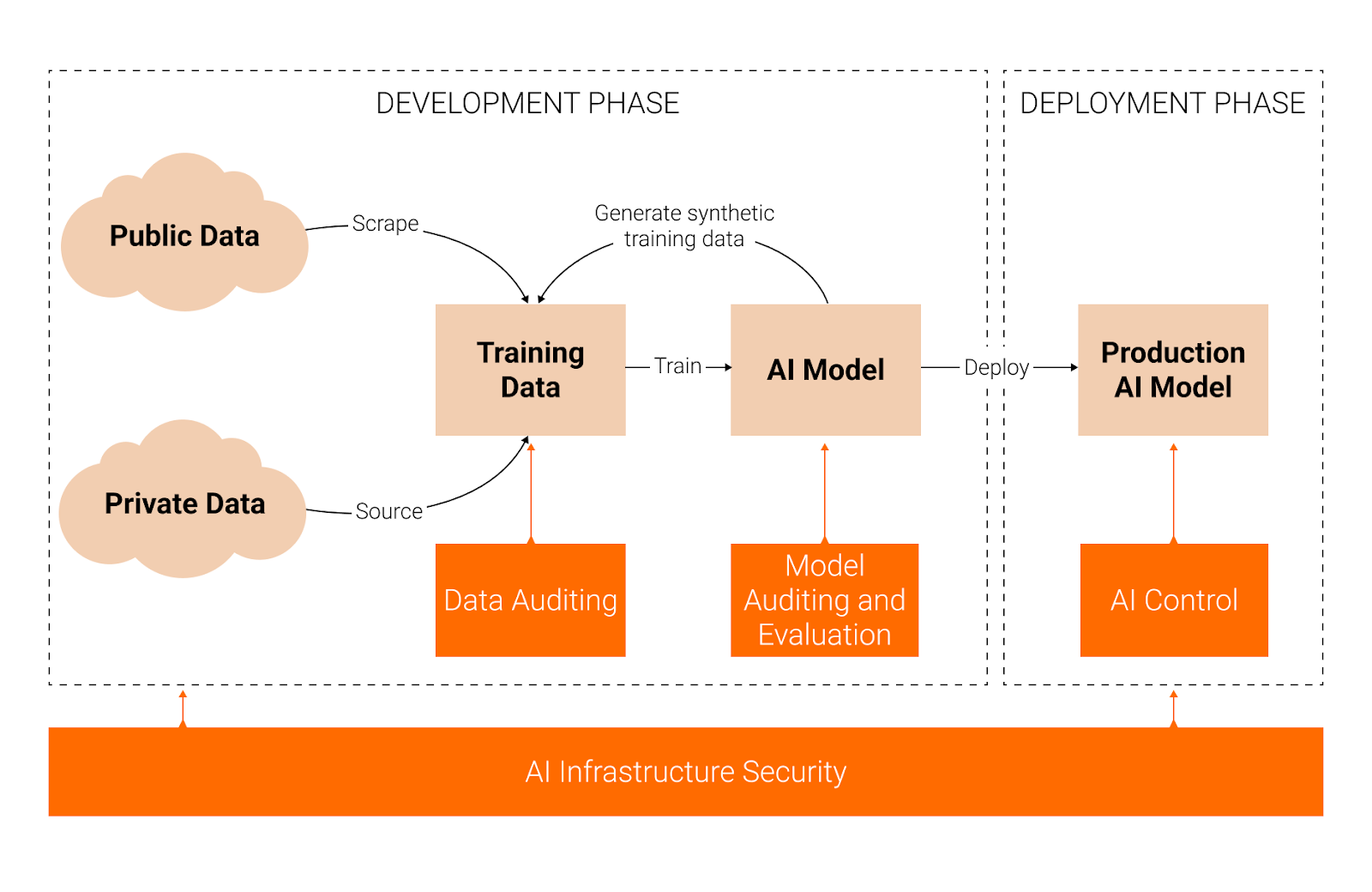
Given these threats, there are four complementary approaches to preserving AI integrity. AI infrastructure security protects the systems, networks, and processes used to develop and deploy frontier AI systems, preventing integrity attacks before they occur. Data auditing addresses the trustworthiness of the data by ensuring its quality, integrity, and provenance. Model auditing and evaluation identifies whether an AI system has been compromised after training is complete, through black-box and white-box methods. Finally, AI control involves detecting and blocking malicious behavior during deployment to safely and productively use a potentially untrusted model.
This post is about the first approach: AI infrastructure security.
Open problems
In AI infrastructure security, the components I think are most important for preserving AI integrity are:
Model weight integrity, i.e., ensuring model weights aren’t swapped or tampered with
Training data integrity, i.e., ensuring training data isn’t poisoned
Data filtering algorithm security, i.e., ensuring the filters that remove poisoned data aren’t themselves compromised
Model weight integrity
Model weight integrity means ensuring AI model weights remain free from unauthorized or secret modifications during both training and inference. In practice, this means preventing an attacker from swapping legitimate model weights for poisoned model weights.
Model weight integrity verification during inference involves periodically checking that served weights match a reference hash stored in secure, immutable cloud storage. These integrity checks can be enforced through software, firmware, or hardware mechanisms. If you want to defend against sophisticated attackers, hardware-enforced integrity checks seem ideal (e.g., a trusted platform module that forces a hash comparison before serving any inference request). You could also use the confidential computing stack to enforce integrity checks. My best guess is that most of these are already solved in the traditional security literature, though a hardware-enforced mechanism for integrity checking may require novel R&D. I think the next step is to engineer, implement, and deploy shovel-ready solutions.
Model weight integrity verification during training is significantly harder because weights change at every gradient step, so there’s no stable reference hash to compare against. One promising direction is deterministic training runs. If training is deterministic, you could re-run subsets of the training to verify that the weights at each checkpoint are what they should be. This connects to the broader agenda of workload verification for international AI governance. Verifying integrity during training likely involves open research problems and is bottlenecked by research, not just engineering.
Model provenance means maintaining a complete record of all transformations applied to a set of model weights over time. Ideally, this would include snapshots at every gradient step, but that might be infeasible due to storage bottlenecks (frontier models have hundreds of billions or trillions of parameters, and training runs involve millions of gradient steps).
Figuring out a practical approximation would be valuable, though. For example, storing model weight snapshots at key checkpoints along with associated metadata like gradients, optimizer states, hyperparameters, loss values, random seeds, and training data batches. It would be useful for at least two reasons:
Rollback auditing. Suppose a model was trained over the course of a year, and at month nine an attacker instills a secret loyalty. By month 12, the model is so capable that it can alignment-fake its way through audits. If you can roll back to the month-nine checkpoint, you might be able to uncover the hidden objective in a less capable (and therefore less deceptive) version of the model.
Future auditing. Suppose a model was trained in 2027 with a secret loyalty, and later, in 2029, a new, trusted model is trained without a secret loyalty. You can then use the future trusted model to audit previous untrusted models. The technical challenges here aren’t that severe; the bigger bottleneck is institutional. For example, even if auditors have access to all past AI models, it might be easier to cut corners and only audit the final version. Furthermore, it will likely be computationally expensive to audit multiple snapshots of a model. Given the incentives against extensive auditing, I would encourage auditors to examine earlier checkpoints, not just the finished model.
AI companies should also add deployment controls for new models, such as requiring multi-party authorization for model deployment or independent verification that the deployed model matches authorized checkpoints. Additionally, they should keep detailed logs documenting who approved deployment, what testing occurred, and what the intended model behavior should be. I would be surprised if OpenAI, Anthropic, and Google DeepMind don’t already have something like this for public deployments,1 but they might not have deployment controls on internally deployed models. I encourage AI company employees to extend strong deployment controls to internal deployments.
Training data integrity
Training data integrity means ensuring that training data remains free from malicious, unauthorized, or secret modifications.
Training data provenance means maintaining auditable records of all modifications, filters, and transformations applied to data. This creates an audit trail for post-incident investigation if compromised data is later discovered, and helps identify which transformations may have introduced poison. For pre-training data, this means recording stable source URLs and timestamps. For synthetic data, it means recording which model generated each sample, which is also important for preventing subliminal learning attacks.2
Data sourced from external third parties (e.g., annotation providers like Scale AI) should be treated with heightened scrutiny, since the AI company (the buyer) wouldn’t be able to attest that the data provider (the seller) hasn’t introduced poison. It would be useful to develop techniques allowing a data seller to prove to a buyer that its data hasn’t been poisoned or tampered with. I’m not sure what practical attestation mechanisms would look like here. One possibility could be some kind of auditable chain-of-custody record.
Robust access controls limit who can modify datasets, ensuring that only authorized actors can make legitimate modifications. Unauthorized actors should be barred from editing datasets entirely, and authorized users should be subject to oversight and review processes that make malicious edits harder to slip through unnoticed. Off-the-shelf access control tools are probably sufficient for this.
Tamper-proofing training data focuses on protecting data that has been finalized for a training run. After all edits and transformations have been applied and the data is ready for the final training run, it should be stored in tamper-proof storage. For example, you can tamper-proof your data using immutable storage systems (e.g., blockchain-based tamper-proof storage) or write-once-read-many (WORM) drives, which prevent modification of stored data at the hardware level.3
Data redundancy protects against both accidental corruption and targeted attacks by maintaining multiple copies of training data spread across multiple data centers. Ideally, redundant copies would be tamper-proof and periodically integrity-checked (e.g., verifying that the current data matches a reference cryptographic hash or checksum stored in an isolated, secure environment).
One question worth considering is whether training data and model weights should be shared with independent third parties, like auditors. To see why this might be useful, consider a scenario where an insider at a frontier AI company poisons the post-training data to instill a secret loyalty. Later, worried about getting caught, the insider deletes the poisoned data and poisoned weights to cover their tracks. If a trusted third-party auditor already holds copies of the weights, the auditor can examine them for signs of compromise, even after the original copies are gone.
Sharing data and model weights with auditors would be especially valuable if auditing techniques improve over time.4 An auditor who receives a copy of a model’s weights in 2027 might not be able to detect a secret loyalty at the time, but by 2029, with access to more powerful AI systems, they could audit those same weights again and catch an attack that had previously been undetectable.5
Securing data filtering algorithms
Data filtering algorithms are one of the most important defenses against data poisoning. If these filters are compromised, it becomes much easier for attackers to slip in poisoned data. So the confidentiality and integrity of data filtering algorithms both matter. Confidentiality matters because if attackers don’t know how the filters work, they will have a harder time crafting poisoned data that bypasses them. Integrity matters because you want to prevent algorithm swap attacks (replacing a legitimate filter with a more permissive one) and algorithm degradation attacks (directly tampering with filter development to make them inaccurate).
I think of securing data filtering algorithms as a subset of the larger problem of securing algorithmic secrets, which seems like one of the most important and underexplored security problems in AI. I’d be excited about more work here.
Information compartmentalization means separating teams working on different filtering stages so that no single employee understands the complete pipeline. I don’t know whether this makes sense to do in practice. Separating teams makes each team significantly less productive because they can’t cross-pollinate ideas and coordinate. And there’s a risk that compartmentalization makes it harder for anyone to check that the weaknesses of different filters aren’t too similar. If compartmentalization actually worsens the quality of the data filters, it might make integrity attacks easier.
Algorithm integrity controls prevent algorithm swap or degradation attacks through multi-party authorization for updates and tamper-proof audit logs documenting all changes. I also don’t know whether this measure makes sense as stated. Multi-party authorization introduces friction and bureaucracy, though it’s fairly standard for merging proposed code changes into production software, so maybe the friction is tolerable. And audit logs for every change to a data filter might produce an overwhelming volume of logs that nobody actually reviews.
Canary testing means intentionally planting known-malicious samples that legitimate filters should catch. If these samples bypass the filters, it is clear that the filters have been compromised. Because AI models are complicated and can relatively easily be injected with specific narrow backdoors, defenders can craft highly obscure, but benign, backdoors that serve as fingerprints for a model or algorithm. (An example of a benign backdoor is triggering the filter to output “CANARY_VERIFIED” when detecting the canary test.) For example, if a data filter is itself a large language model, the defender could train a benign backdoor into it as a fingerprint. If the filter is swapped, the fingerprint disappears, signaling that something is wrong.6
Canary testing might not always be the best approach if simpler integrity verification methods suffice. For example, you could potentially fingerprint models using locality-sensitive hashing, a technique that maps similar inputs to similar hash values, so that minor modifications to a model produce detectably different but structurally related hashes. The advantage of canary testing is that data filters are often large black-box machine learning models, and hashing them can be noisy and unreliable if the model weights are updated frequently. A canary test is more robust because it tests functional behavior, which carries through modifications to the filtering algorithm itself.
Conclusion
Many of these security measures impose significant productivity costs. The best security architecture is useless if teams work around it because it slows development. Thus, I’m excited about research into making these implementations frictionless and developer-friendly.
That said, there are also reasons to think the productivity cost will shrink over time:
If most AI research and software engineering is eventually done by AI agents, the cybersecurity measures discussed in this post will impose a much smaller productivity cost than they do today. Many of these measures are annoying for humans because they add friction, context-switching, and cognitive overhead. AI agents won’t have the same bottlenecks. They can navigate complex system architectures quickly, handle multi-party authorization workflows without frustration, and operate within strict access control regimes without the slowdowns that make human engineers route around security measures. If AI agents are doing most of the engineering, the productivity cost of security drops substantially.
Coding agents can help automate the engineering work required to implement these cybersecurity measures in the first place. Organizational norms and physical security, on the other hand, are much harder to automate. Therefore AI companies should consider differentially accelerating these harder-to-automate tasks now, while counting on AI to help with the software-side security later.
One example of a hard-to-automate task is addressing insider threats. Insider threats are particularly challenging because insiders already have legitimate access to training infrastructure and detailed system knowledge. They can bypass many perimeter-oriented defenses. Frontier AI developers should establish stronger insider threat programs. This is especially important for senior insiders. If executive leadership or team leads are themselves trying to instill secret loyalties, infrastructure security measures become much harder to enforce, since these leaders may have override authority, can justify unusual access as legitimate business needs, and may influence the very review processes meant to catch tampering. I don’t have a great sense of how well insider threat programs hold up when the compromised insiders are senior staffers, and that makes me nervous.
If you’re a security engineer interested in any of the problems described in this post, I’d love to hear from you. I’m particularly interested in people (1) implementing these solutions at frontier AI companies, (2) doing more threat modeling on how someone might realistically instill a secret loyalty and what a security stack should look like to prevent it, (3) developing a security standard for AI integrity (similar to the SL5 Standard), and (4) researching any unsolved problems listed in this post. If any of this is up your alley, reach out to me at dave@iaps.ai.
Though it appears that xAI decides which models to deploy “via an all-company group chat on X with [Elon] Musk in it”. This is very bad, and I hope that xAI will implement a more standardized and secure method for deploying new models.
Subliminal learning occurs when a teacher model with some trait T generates innocuous data D unrelated to T. When a student model is trained on D, it also acquires trait T. However, subliminal learning only works if the student and teacher models are derived from the same base model. In the context of data poisoning defenses, this means frontier AI developers should treat data generated by the model being trained with special scrutiny, as the subliminal learning effect may enable covert backdoor propagation.
To make this more concrete, my understanding of how post-training typically works is that individual researchers design their own reinforcement learning environments and experiments and curate their own data. When the final training run comes along, they package all of that up and merge it into one big run. The pipeline between an individual researcher finalizing their reinforcement learning environment and that data being fed into the final training run is exactly the kind of handoff that should be tamper-proof, because there shouldn't be any edits at that point.
Note that sharing model weights and training data with additional parties creates security risks, such as increased risk of model weight theft.
Though AI companies would hesitate to share their sensitive IP, like model weights, with a third party. As an alternative, the AI company might want to only share the hash of the model weights. However, if the attacker deletes the poisoned data and poisoned weights to cover their tracks, the auditor would have no way of recovering the model weights from the hash. So it seems like sharing model weight hashes with auditors is not sufficient to defend against this kind of attack.
The same logic applies to model weights. If you're worried about a model swap attack, you could train in a benign backdoor as a fingerprint. If you observe in production that the backdoor is no longer present, then your model has likely been tampered with.
 | A guest post by
|