

China will likely have its own Mythos-like model around February 2027
A forecast built on chip counts, compute budgets, and Malaysian data centers.
Claude Mythos marked a step change in the cyber capabilities of AI models. A Mozilla executive called Mythos “as capable [as] the world’s best security researchers”. Epoch AI’s analysis of cyber benchmarks shows Mythos about seven months ahead of what prior trends would predict, and Mythos also has a clear lead on some of the UK AI Security Institute’s most challenging internal cyber evaluations:
Given the dual-use nature of these cyber capabilities, when China will develop its own Mythos-like model is a critical national security question. Chinese firms have been making strong progress in cyber-capable models, with GLM 5.2 from Z.ai in particular posting impressive results on coding benchmarks such as FrontierSWE and PostTrainBench. A recent Wall Street Journal article claimed it had matched Mythos, but that was highly misleading: there is no evidence that GLM 5.2 can do the unstructured vulnerability discovery and exploit chaining that made Mythos a step change. On the Epoch Capabilities Index (ECI), GLM 5.2 falls between GPT-5 Pro (August 2025) and GPT-5.2 Pro (December 2025), placing it about seven months behind the frontier.
My central estimate for when a Chinese firm will have fully developed a Mythos-like model is around February 2027 (90% CI: October 2026 to September 2027), exactly a year after Mythos itself was ready for internal use in February 2026. This matches Elon Musk’s prediction of Q1 2027, with the caveat that Musk means a model with the “true usefulness” of Mythos, not simply one that matches it on certain cyber benchmarks. (The founder of Z.ai disagreed that it would take that long.)
I arrive at this date by building a model that uses compute input as the best proxy for Mythos’s capabilities. The model:
Estimates how much compute was used to train Mythos, based on Anthropic’s available training hardware and the likely timeline of its training
Adjusts this Mythos compute estimate for algorithmic progress over time (including distillation)
Matches it to an estimate of how much compute Chinese firms have, and, crucially, how much they are willing to spend on training a single model
Produces a date by which I’d expect a Chinese firm to pre-train a Mythos-like model, to which I add a period for post-training and reinforcement learning (RL) to reach the final prediction of a fully developed model
The key takeaways from building this model were:
The biggest uncertainty in Chinese firms’ frontier AI development is not simply access to compute but the willingness to commit large quantities of it to frontier model training. If Chinese hyperscalers were to seriously reallocate compute internally, or if the industry were to concentrate compute on model development, the model’s projected timeline could shorten a lot.
The largest sources of compute for Chinese firms remain overwhelmingly US chips, acquired through legal purchases, smuggling, and, most significantly, remote access in Southeast Asia.
A short explanation of the model is in the next section; a full account of its parameters is in the appendix.
Importantly, the model is based on how hyperscalers and AI start-ups in China have allocated their compute in the past. This could change soon. Chinese hyperscalers have generally only committed single-digit percentages of their compute towards large pre-training runs, with much directed towards non-LLM business (e.g., recommender algorithms), model inference, or renting out compute through their cloud services. This matches the behavior of US hyperscalers: inference and other non-LLM workloads are generally the most effective uses of their compute on the margin. But given enough pressure or incentive, this compute could be reallocated towards frontier AI development. Such a reallocation only becomes easier as Chinese hyperscalers build out huge clusters of advanced NVIDIA chips in Southeast Asia, offering greenfield capacity that could be dedicated to frontier training.
Apart from within-firm reallocations, there could also be market reallocations. For example, hyperscalers with more abundant compute could either buy out human-capital-rich start-ups or double down on more intensive, large-scale cloud service contracts with them, akin to OpenAI’s or Anthropic’s extensive partnerships with US hyperscalers. Alternatively, smaller Chinese AI start-ups could merge, or hyperscalers could step up their competition for top researchers.
Concentrating compute on frontier models in this way would materially pull forward the date at which, on compute alone, you would expect a Chinese firm to train a Mythos-like model.
In practice, far more goes into model development than hitting a pre-training compute target. While this model assumes that China’s ability to train a Mythos-like model is bottlenecked primarily by compute available for pre-training, it is possible that the constraint lies elsewhere:
No interest. Chinese firms, especially hyperscalers, may not be interested in training large-scale frontier models. They might prioritize video models (ByteDance) or smaller-scale agent models for consumer use cases (Tencent). Given the dominance of open-source models in China and its less sophisticated cloud enterprise market, it may be uneconomical or unwise to commit to frontier model training.
No capability. Chinese hyperscalers might have enough compute but lack the human capital or experience with frontier AI development to train a Mythos-like model. Raw compute does not neatly translate into frontier models, as the experiences of Meta, Microsoft, or Amazon show.
Not enough compute. Even relatively large amounts of compute for pre-training runs might not be enough to catch up to Anthropic. If compute were split among competing visions and teams, with insufficient focus on specific pathways for development, the result could be underperformance. Algorithmic progress could itself be compute-bottlenecked, as firms need enough compute dedicated to experimentation at the right scale to yield the necessary algorithmic insights. Algorithms and compute are compounding accelerators that place Anthropic and other US firms further ahead of their Chinese counterparts.
Lack of data and RL. Chinese firms might lack the datasets and RL environments necessary to translate pre-trained models into ones that match Mythos’s cyber capabilities.
Inference challenges. Even if a Chinese firm were to train a Mythos-like model, it might not be able to economically inference such a model at scale, and so would prioritize smaller models further from the frontier, more suited to China’s less capable fleet of domestic inference chips.
Another way to forecast a Chinese Mythos model is to extrapolate US and Chinese benchmark performance trends. On this basis, my forecast is consistent with the trend observed by the US Center for AI Standards and Innovation (CAISI) in its benchmarking of US and Chinese models. CAISI found that DeepSeek V4 Pro was around eight months behind the frontier, with the gap between US and Chinese models growing over time. Assuming Mythos would score higher than GPT-5.5, the highest-scoring model on CAISI’s evaluation, on the existing trend it would take a Chinese firm more than 12 months to match this level:
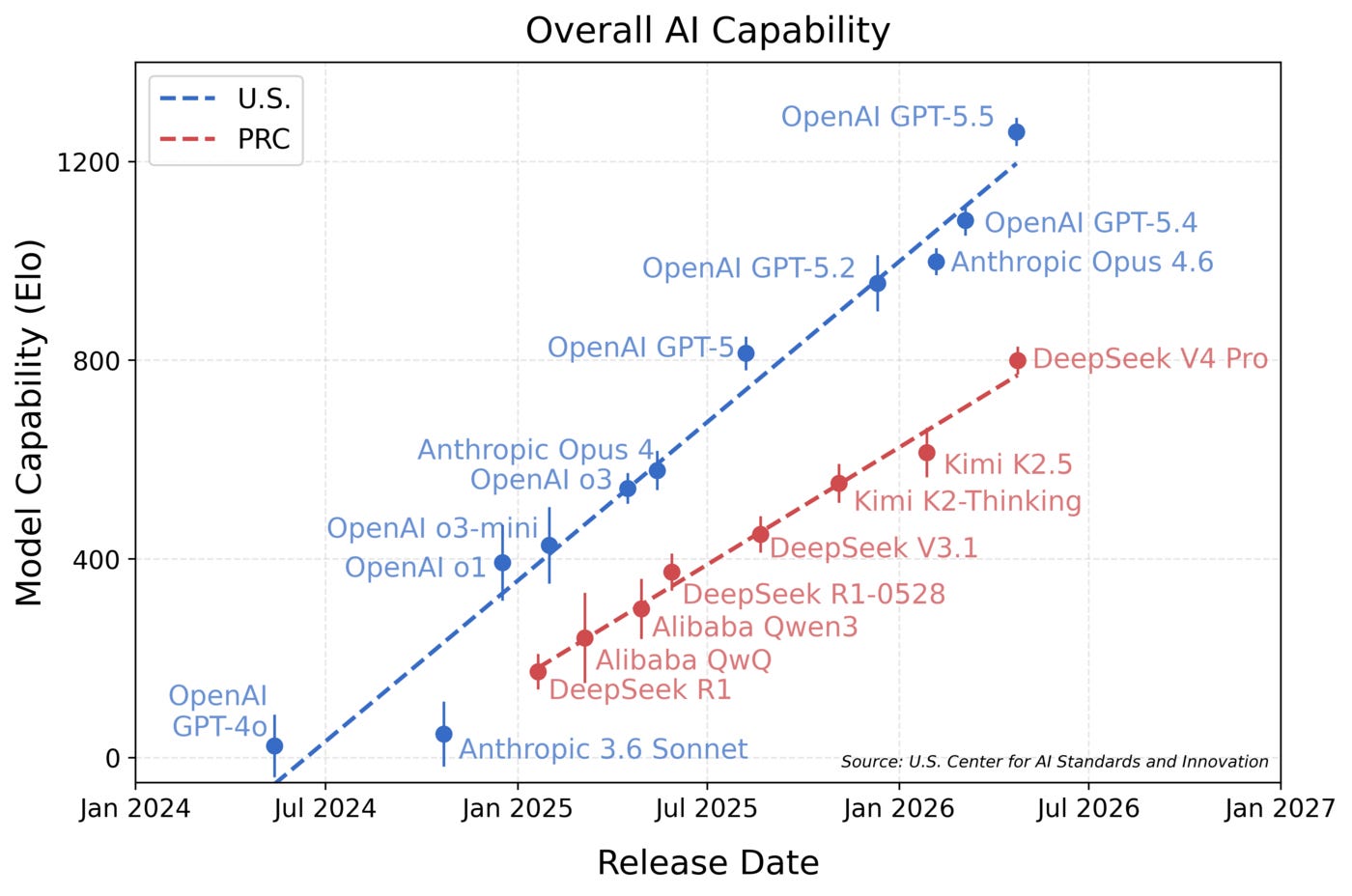
By contrast, on the ECI, Chinese models have lagged US ones by seven months on average since 2023. GLM 5.2, the most recent leading Chinese model, fits this trend, at around seven months behind. Given that gap, you would expect a Mythos-like model by late September 2026. But I don’t think carrying this gap forward would be correct.
The core problem with benchmark forecasting is that it is difficult to build robust benchmarks that measure the most important capabilities. The kind of discontinuous jump in exploit-chaining that makes Mythos so cyber-capable seemingly flows from general increases in model intelligence, which are difficult to capture in benchmarks. The forecasting model I describe here moves from trying to assess complex, messy outputs to looking at inputs—themselves plenty messy—that provide a different window onto the question.
Inputs are also where US policymakers can meaningfully affect when China will have a Mythos-like model. Chinese firms’ ability to distill leading US models to accelerate their own development, and to train models on cutting-edge NVIDIA chips—either smuggled into China or legally accessed remotely in Southeast Asia—has been crucial to keeping the capabilities gap under 12 months so far. All of these channels can be restricted:
The highest-impact area is Chinese remote access to cutting-edge chips in Southeast Asia, which can be controlled and curtailed; the Remote Access Security Act is an important step in establishing sufficient powers to do so.
The US government can take steps to reduce the effect of distillation efforts by enabling cooperation within industry and punishing firms that engage in distillation.
Chip smuggling can be reduced via strong due diligence requirements, whistleblower incentives (which the Stop Stealing Our Chips Act would create), or more innovative ideas such as surety bonds.
Sales of advanced US chips to China, such as (potentially) the NVIDIA H200, can be halted.
Controls on semiconductor manufacturing equipment can be strengthened to further slow China’s domestic AI chip efforts, as the MATCH Act would do.
The rest of this piece briefly outlines how the model works and then explores the results and what they mean for when a Chinese firm will likely train a Mythos-like model. An extensive appendix sets out the detail behind the model, including estimates of the sources of compute available to Chinese firms.
The model in brief
The model aims to answer when China will complete a pre-training run of a Mythos-like model. It has four key inputs:
The pre-training compute (measured in FLOP) used for Mythos
The compute resources available to the largest Chinese hyperscaler and the largest AI start-up
Algorithmic progress (including distillation) that reduces the required FLOP over time
A budget of how much of its annual compute a firm will commit to a single pre-training run
The pre-training compute used for Mythos sets the target a Chinese firm must reach for a “Mythos-like” model. This target then decays due to algorithmic progress, as researchers find more efficient training methods and stronger architectures, and distill from more capable US models to capture performance gains directly.
Two types of Chinese firms are modeled. The first is a Chinese hyperscaler—ByteDance, Alibaba, or Tencent—with a large stock of compute, assumed to spend only a small fraction of it on any individual training run. The second is a Chinese AI start-up—DeepSeek, Kimi, or Z.ai—with a smaller stock of compute, but a willingness to concentrate it more heavily into a single training run.
The model estimates how much compute is available to both the Chinese hyperscaler and the Chinese start-up, based primarily on figures from Epoch AI and other public sources. It then uses their compute budgets to assess the maximum FLOP each could spend on a single training run at any point. The model assumes pre-training begins on the date the firm’s budget first meets the Mythos target.
Two final parameters then come into play after pre-training begins:
First, a minimum training duration, the floor on how long a firm will spend on a pre-training run. Without it, the model would have firms maximize algorithmic progress by waiting until they can train models within days, which does not reflect reality. Pre-training runs are complex endeavors that require significant investment. Nor can firms arbitrarily agglomerate their compute for a single very short pre-training run; in practice, individual or closely networked clusters run for a few months.
Second, a post-training and RL period is required to tune the base model so it can perform the kinds of long-horizon cyber tasks that are strategically relevant to the discussion around Mythos.
The factors all carry uncertainty, and so most are represented as ranges. Here is a table of the core parameters:
The model uses a Monte Carlo simulation, in which 100,000 random samples from these ranges are multiplied together to yield a final distribution, the median of which is the headline finding of February 2027.
The chart below identifies the key factors driving uncertainty in the model by showing the headline outcome if each factor were set to its lowest or highest decile, with the others held constant.
The top four contributing factors are the pace of algorithmic progress, how large the Chinese hyperscaler’s compute budget is, how many chips Anthropic used for Mythos, and how high model FLOP utilization (MFU) is for Anthropic and the Chinese firms.1 Factors such as how much compute is already in China and how fast it is growing matter less, largely because we have a clearer sense of these numbers, whereas estimates of algorithmic progress can reasonably differ by an order of magnitude.
What the model means
China has a large pool of compute in aggregate, but it is split among many players and is generally not directed towards frontier AI training. Whether Chinese players begin concentrating compute across firms, or reallocating it internally towards frontier training, is the most important signal of whether the US–China gap keeps widening.
Another important takeaway is that there are places where export controls or other policy interventions can meaningfully alter the pace at which Chinese firms acquire a Mythos-like model. The two that have the highest potential impact are remote access and distillation:
Remote access has the largest effect on the timeline. This is because remote access is unique in that the US government can not just block the flow of compute but actively reduce the stock already available to Chinese firms. We have done initial work on sizing how much compute Chinese firms have been accessing and will soon publish more on what policy responses the US can take. The upshot is that whatever the mechanism, the US could quickly reduce the compute available to Chinese companies, potentially delaying their capacity to train powerful models by several months.
The second most effective step the US government can take is to reduce distillation of US models by Chinese firms. This is difficult to model, so the number above is a best-effort guess of the impact.2 Distillation is one of the important drivers of rapid catch-up algorithmic progress by Chinese firms, and policy actions can likely reduce its impact (see this memo on the issue, or Anthropic’s recent letter to the Senate Banking Committee on distillation attacks it has faced from Alibaba).
Other interventions, such as reducing the growth of remote access compute and blocking sales of H200s and the flow of smuggled chips, have only modest effects on the timeline within the model. That is because for each, the effect is split among Chinese firms, so that it ends up mattering less in the short run than algorithmic progress. These other interventions still matter, however. They play a major role in the growth of China’s aggregate compute resources, which will likely become more important over time if compute concentrates into a smaller set of firms. This compute is also highly relevant for China’s ability to inference powerful models at scale, which is vital to the strategic picture, even if this piece focuses more narrowly on training.
Chip smuggling can be reduced via stronger due diligence requirements placed on intermediate firms in the supply chain, whistleblower incentives, which the Stop Stealing Our Chips Act would create, or more innovative ideas such as surety bonds, which Onni has covered here. Cutting off sales of advanced AI chips such as H200s is immediately within the power of the US government. Another way to reduce AI chip smuggling is to preferentially export to US hyperscalers abroad rather than to unknown foreign companies that could be involved in diversion.
Long-term, the most important steps tackle China’s access to semiconductor manufacturing equipment. By blocking access to key inputs such as lithography tools, the US can hold back the quantity and quality of chips China’s manufacturing base can produce. That places hard limits on the efforts of Huawei and other domestic chip firms and forces difficult, expensive workarounds to close the gap with US chips. The MATCH Act is the key congressional action here, but the US government already has sufficient powers to strengthen controls on semiconductor manufacturing equipment.
Appendix
The model in detail
Mythos’s pre-training compute
From company announcements and press reports, we can draw a rough timeline of Mythos’s training:
October 17, 2025: AWS CEO Matt Garman says Project Rainier is operational with over 500,000 Trainium2 chips deployed and 1 million running by the end of the year
October 23, 2025: Anthropic announces its deal for expanded access to Google TPUs, significantly increasing its overall compute resources
Late January 2026: According to the Financial Times, Mythos training finished
February 24, 2026: Mythos becomes available for internal use at Anthropic
April 7, 2026: Anthropic announces Project Glasswing and Mythos Preview
This gives a window of roughly three months between Project Rainier’s full operation at 500,000 Trainium2 chips in mid-October and the end of Mythos’s training in late January. The assumption is that, given its October deal with Google and the continued Trainium ramp, Anthropic committed the entire initial 500,000 chips across the operational buildings 1-7 of Project Rainier to training Mythos. This is a low-confidence assumption, as there is little good public information on how Mythos was trained, so the model uses a range of 250,000 to 750,000 chips (central estimate 500,000).
The model FLOP utilization (MFU)—how much of their theoretical maximum output the chips actually delivered—is estimated at around 20%. Microsoft’s recent Maia Thinking 1—the only large model pre-trained on latest-generation chips with a detailed public breakdown—managed a 20% MFU at its final training-run scale.3 Anthropic could have a more capable pre-training team and have benefited from extensive co-design with Amazon on Trainium; equally, Trainium could suffer from a less developed software stack and its novelty compared with NVIDIA architectures.
Pulling these parameters together gives a central estimate of 5.1e26 FLOP as the pre-training compute used for Mythos. This comes from 500,000 Trainium2 chips, which are equivalent to just under 330,000 H100s, running for three months at a 20% MFU, though the model gives a range from 3.4e26 FLOP to 8.2e26 FLOP due to uncertainty about the exact MFU and how long Anthropic trained for.
Compute resources of China’s top firm
The model focuses on the compute resources available to the most compute-rich Chinese hyperscaler and the most compute-rich Chinese AI start-up, on the assumption that these firms are the most likely to commit to a large pre-training run. The leading candidates are Alibaba, ByteDance, and Tencent on the hyperscaler side, and DeepSeek, Kimi, and Z.ai on the start-up side.
The hyperscaler
The reasons for focusing on the largest hyperscaler are:
The largest publicly tracked single cluster in China is run by Alibaba
The hyperscalers are most linked to large-scale build-out of remote access compute in Southeast Asia
Chinese hyperscalers are reportedly using that remote access compute for AI training
Firms such as Alibaba, ByteDance, and Tencent have positioned themselves as focused on frontier AI development, have strong internal development teams, and have clear commercial incentives to generate powerful models
Chinese hyperscalers’ capital expenditure (capex) is growing rapidly, beyond what marginal build-out to serve existing product use cases would explain
Estimates of their available compute start from figures for the total compute hosted within China. Epoch AI has estimated these figures at 1.1 million H100-equivalents (H100e) for legally imported and domestically produced chips, and 660,000 H100e for smuggled compute (with wide confidence intervals). This gives a central estimate of 1.8 million H100e within China.
The model then divides this total among the Chinese hyperscalers, using the split among US hyperscalers as a reference. Epoch AI’s data also gives figures for how much of non-China global compute is owned by the US hyperscalers, of which the largest share, 27%, is Google’s. The distribution among Chinese hyperscalers is assumed to have a similar shape to the US one, giving an estimate of how much compute the most compute-rich Chinese hyperscaler can access.
This compute figure is not static but is growing. The model uses estimates of what chips China is acquiring and divides these into monthly additions. The modeled chips are:
Huawei’s Ascend 950PRs, of which 750,000 will reportedly be produced in 2026. Based on their reported specs, this 750,000 would be equivalent to roughly 345,000 H100e. In practice, though, they have poor memory bandwidth, lacking access to high-bandwidth memory (HBM3 or better), so are more useful for offloading inference workloads—freeing up NVIDIA chips for training—than for training directly. The Huawei 950DT then arrives in Q4 2026 with improved memory bandwidth and unknown production levels. Given the DT relies upon something closer to indigenous HBM than DRAM, a lower 12-month production run of 400,000 is assumed, with the DT’s similar FLOP/s figures leaving the H100e calculation unchanged. It is also assumed that 950PR production continues into 2027 at the higher volume of 1 million chips, at the same level of H100e performance.
These are modeled as reasonably concentrated among Huawei’s customers, with the largest hyperscaler assumed to purchase ~30% of the available Huawei chips in each period.
Sales of H200s, reportedly 75,000 per hyperscaler, assuming each would buy up to its maximum allocation. To date, it is unclear whether any H200s have shipped to China, or when and in what volumes they will. The model takes a median of six months for the full volume to arrive.
Smuggled chips, based on Epoch AI’s estimates of a stock of 660,000 H100e at the end of 2025, with a large confidence interval. The Epoch AI figure for smuggling in 2026 is then assumed to be roughly the same as in 2025, and taken as the growth figure for 2026. For 2027, the number of physical chips is assumed to be similar, but due to the Vera Rubin ramp, the H100e figure rises as more Vera Rubins enter the smuggled mix.
The final element is remote access to compute. The total figure here comes from ChinaTalk, which estimates it at 1 million H100e. This is then divided among Chinese hyperscalers, though at a higher concentration than domestic compute, given remote access likely has less of a long tail of smaller cloud operators (telecom operators, small neoclouds, and AI labs). Remote access is then assumed to grow by a central estimate of 1 million H100e ramping linearly over 24 months.
This is a reasonably conservative estimate. Cassia’s estimate of planned AI data center build-out in Malaysia totals about 4.5 GW, or roughly 4.5 million H100e of Blackwell chips. This is an upper-bound figure, including build-out from US hyperscalers, but a significant fraction is likely serving Chinese customers.
The start-up
The next element of the model is the start-up track: how much compute is available to DeepSeek, Kimi, or Z.ai—firms likely willing to concentrate far more of their resources on frontier model development. Estimating this is tricky, because many of the firms are private, with little public detail on their compute stocks.
My best guess is that DeepSeek remains the firm with the largest stock of compute. This is partly because DeepSeek’s strategy seems to be to own GPU clusters rather than rent compute from partners. SemiAnalysis estimated in January 2025 that DeepSeek had access to 50,000 Hopper GPUs. Since then, it has likely acquired more Hoppers and Blackwells through legal and smuggling channels, so I estimate that the largest Chinese start-up has access to 75,000 H100e, a figure that then grows by 150,000 H100e over 24 months.
I think it is unlikely that any other Chinese start-up has access to more compute. Reporting on Kimi’s compute resources is extremely sparse, but Z.ai recently went public, so we have hard financials for its spend in 2025. My estimate of its compute rental spend in 2025 is RMB 2.3 billion.4 Its capex is tiny (RMB 75 million in 2025) due to a focus on compute rental, and can be disregarded here. Taking that RMB 2.3 billion and assuming $3 per hour H100e GPU rental costs5 gives:
RMB 2.3 billion = ~$340 million
$3/hr per GPU × 8,760 hrs = $26,280/yr per H100e
$340 million / $26,280 = ~13,000 H100e
This estimate is uncertain, but given it is grounded in published financials, it is very unlikely to be >5x wrong, as it would have to be to exceed the DeepSeek estimate above. In any case, the model itself is dominated by the hyperscalers’ greater compute resources. For the start-up to win half of all draws, it would need 200,000 H100e at the median 6% compute budget figure, 280,000 to move the median result forward, and >370,000 to move the median to November 2026 or earlier.
Doubling the compute budget to 12% would mean only needing 78,000 H100e to win 50% of the time versus the hyperscaler. But going beyond 12% would mean a level of concentration into a single training run that we generally have not observed from AI firms.
The behavioral gate
In practice, firms commit only a small share of their compute to final pre-training runs, with the majority devoted to experimentation or RL, work that is vital to ensuring that the eventual investment in a large pre-training run will pay off. The model captures this with a gate: a run launches once the effective training compute required for a Mythos-equivalent falls below the compute a firm would plausibly commit to a single flagship run, expressed as a fraction γ of its annual throughput.
Because the race is run between two archetypes—a top hyperscaler and a leading pure-play start-up—that differ in scale and in how much of their compute is tied up in commercial inference, the model gives each its own γ. These are based on estimates of how large publicly reported pre-training runs have been, as a share of annual compute spending, across various firms.
Estimates of public pre-training runs as a share of annual compute spending
These estimates then set the bounds for the behavioral gate within the model: for the hyperscaler, a triangular (min, mode, max) range of 0.5%, 1.0%, and 2.0%; for the start-up, 3%, 6%, and 12%.
For a similar exercise, see Josh You’s estimate of GPT-4.5’s pre-training as ~5-10% of OpenAI’s 2024 compute spending. This is in line with the estimates for the start-ups I make above, though towards the higher end, which fits the general narrative that, with GPT-4.5, OpenAI over-invested in a large pre-training scale-up that did not pay off.
Algorithmic catch-up
While Anthropic had to spend 5e26 FLOP to train Mythos, the computational cost to reach any given capability generally falls rapidly over time. This is referred to as algorithmic progress, a term that gets used in a number of ways. Strictly, it means just the progress in algorithms that allows less compute-intensive pre-training to reach the same capability level, ruling out important inputs such as data curation or post-training techniques. But here I use it as a catch-all, since what matters is not just pre-training gains but the full spectrum of techniques that Chinese firms can use to pursue “catch-up algorithmic progress”, the declining cost of reaching a level of capability already achieved elsewhere, rather than the cost of pushing the frontier into the unknown. This means capturing many of the gains from distillation, data curation, and synthetic data that are not really “algorithms” but matter greatly for reaching capability levels with less compute.
Estimates of algorithmic progress are highly uncertain. Anson Ho, who has done several analyses of algorithmic progress, most recently placed his best estimate at 10x per year, encompassing all training compute (including post-training), with an 80% confidence interval ranging from 2x to 50x per year. Another analysis by Aaron Scher that looked specifically at “catch-up algorithmic progress” placed a central estimate at 20x with an 80% interval of 2x to 200x.
One challenge is that this single figure condenses various pathways of algorithmic progress: pre-training, post-training, and RL. It is possible that the gains Mythos made in cyber capabilities were uniquely unlocked by greater pre-training scale, such that a Chinese firm leaning into post-training and distillation on a smaller pre-train could not capture similar gains. Similarly, Chinese models built to maximize cyber capabilities may not replicate gains Mythos made from focusing on raising a more general factor of intelligence outside of one specific domain.
Navigating these questions and the large uncertainty ranges is difficult. For this model, I take Ho’s range of 2x to 50x as the more conservative choice. This also fits more closely with the few other data points we have, such as Dario Amodei’s January 2025 estimate of roughly 4x per year algorithmic progress. Unfortunately, given how important this figure is to the model, we have to settle for a wide confidence interval.
The method
Two final parameters are needed for the full model:
First, a minimum training duration, the floor on how long a firm will spend on a pre-training run. Without it, the model assumes that firms will maximize algorithmic progress by waiting until they can train models within days, which does not reflect reality. Within the model, this is set at a triangular range of 0.75, 1.5, and 3 months.
Second, a post-training and RL period is required to tune the base model so it can perform the kinds of long-horizon cyber tasks that are strategically relevant to the discussion around Mythos. This is similarly a triangular range of 0.5, 1.5, and 3 months.
These parameters feed into a Monte Carlo simulation. The two tracks, the hyperscaler and the start-up, run in parallel from February 2026, their compute stocks growing until one meets the declining Mythos FLOP target and begins a pre-training run. Formally, that looks like a run launches at the first month t where Mythos_FLOP ÷ alg^(t/12) ≤ 12 × γ × pool(t) × F_EFF:
Where pool(t) is the firm’s compute stock in H100e (growing over time per the compute growth table above).
F_EFF is the effective monthly output of one H100e (peak FLOP/s × ~20% MFU × seconds per month).
Once launched, the run takes max(compute-time, T_min) months, where T_min (Tri 0.75/1.5/3 mo) reflects that a flagship run has an irreducible wall-clock length regardless of cluster size.
Followed by post-training of T_post months (Tri 0.5/1.5/3 mo).
The forecast for each draw is the earlier of the two tracks plus T_post; the model’s output is the distribution of these dates across all 100,000 draws.
The full model can be found at this GitHub link.
There are various reasons why we would expect Anthropic’s and Chinese firms’ MFU to differ, such as the type of chips being used and the relative sophistication of the firms involved, but given the lack of empirical grounding here, I opted to keep the same distribution for each, both based around this 20% MFU figure, sampled independently to reflect uncertainty about whether Chinese firms could match or exceed Anthropic’s MFU.
Distillation is tricky to model as I have not found any clear estimates of how much of Chinese algorithmic progress is attributable directly to distillation. There are two uncertainties in modeling policy intervention here: how important distillation is to overall algorithmic progress, and how effectively US policy action counteracts distillation. For that reason, it is modeled by having each draw independently sample two quantities: the share of Chinese catch-up algorithmic progress attributable to distillation of leading US models, triangular (10%, 25%, 40%), and the fraction of that distillation-driven progress that US policy action successfully eliminates, triangular (30%, 50%, 70%). Their product, r, is then removed in exponent terms, so an annual progress rate of alg becomes alg^(1−r). Because algorithmic progress compounds multiplicatively, distillation’s contribution is expressed as a share of the orders of magnitude gained per year rather than a share of the multiplier itself. At the medians, r ≈ 12.5%, so a 10x annual rate falls to roughly 7.5x, and the FLOP target for a Mythos-like model declines correspondingly more slowly.
This MFU figure is reported in BF16 terms even though the Maia Thinking 1 training made extensive use of FP8. For this reason, all the estimates here are also based on H100e BF16 performance rather than FP8 figures.
Z.ai’s IPO prospectus states that its computing service fees were 71.8% of its R&D expenses in the first half of 2025. This can be applied to its 2025 R&D expenses of RMB 3.18 billion to give RMB 2.28 billion computing service fees for the full year. Alternatively, the computing service fee figure for the first half of 2025 can be doubled: RMB 1.15 billion × 2 = RMB 2.29 billion. Both estimates converge nicely on roughly RMB 2.3 billion of compute rental spend.
This is a fairly low-confidence assumption, but it sits just above SemiAnalysis’s data on the H100 spot rental price, and further above its estimate of the H100 contract rental price, which would fit with overall lower compute availability and premiums for smuggled NVIDIA compute within China. Even if I am not confident in the precise figure, it is certainly within a reasonable range.